출처 : http://database.sarang.net/?inc=read&aid=25686&criteria=oracle&subcrit=&id=&limit=20&page=3
MONTHS_BETWEEN 과 ADD_MONTHS 함수는 잘 이해하고 사용하셔야 합니다.
오라클 매뉴얼을 보시면 아시겠지만...
위의 경우를 놓고 설명하자면,
1. 첫번째 v_a_dt : 20020228
두번째 v_b_dt : 20011128
-> 위의 경우와 같이 뒤의 일자부분이 동일한 경우에, MONTHS_BETWEEN 함수는 두 일자의 월간격 즉, 3을 리턴합니다.
3. 첫번째 v_a_dt : 20020228
두번째 v_b_dt : 20011130
-> 이 경우는, 달력을 보시면 아시겠지만, 두 날짜 모두 그 날짜가 속한 달의 말일입니다. 이 경우에도 위의 1의 경우와 마찬가지로 두 일자의 월간격 3을 리턴합니다.
2. 첫번째 v_a_dt : 20020228
두번째 v_b_dt : 20011129
-> 마지막으로 1번도 3번도 해당하지 않는 경우에는 다음과 같이 계산됩니다.
2001년 11월 29일 + 1달 = 2001년 12월 29일
2001년 11월 29일 + 2달 = 2002년 01월 29일
2001년 11월 29일 + 3달 = 2002년 02월 29일 인데, 28일까지 밖에 없으므로 3달 보다는 적은 2.xxxxxxx 달이 될 것입니다.
그러면 뒤에 소수부분은 어떻게 계산할까요?
2002년 01월 29일과 2002년 02월 28일은 30일의 차이가 나므로, 30일을 무조건 31로 나눈 30/31이 됩니다.
따라서 2번의 경우에는 MONTHS_BETWEEN 함수는 2+30/31을 리턴합니다.
계산해 보시면 아시겠지만, 확실히 30/31=0.96774193548387096774193548387096774194....... 인 값이 나옵니다.
이해가 되셨는지 모르겠네요.
-- SQL 쿼리 질문은 SQL 까페에서... http://cafe.daum.net/oraclesqltuning
WITH T AS
(
SELECT TO_DATE('20120229', 'YYYYMMDD') SDT, TO_DATE('20120329', 'YYYYMMDD') EDT FROM DUAL
UNION ALL SELECT TO_DATE('20120229', 'YYYYMMDD') , TO_DATE('20120330', 'YYYYMMDD') FROM DUAL
UNION ALL SELECT TO_DATE('20120129', 'YYYYMMDD'), TO_DATE('20120228', 'YYYYMMDD') FROM DUAL
UNION ALL SELECT TO_DATE('20120130', 'YYYYMMDD'), TO_DATE('20120228', 'YYYYMMDD') FROM DUAL
UNION ALL SELECT TO_DATE('20120201', 'YYYYMMDD'), TO_DATE('20120229', 'YYYYMMDD') FROM DUAL
UNION ALL SELECT TO_DATE('20120131', 'YYYYMMDD'), TO_DATE('20120229', 'YYYYMMDD') FROM DUAL
UNION ALL SELECT TO_DATE('20111130', 'YYYYMMDD'), TO_DATE('20120331', 'YYYYMMDD') FROM DUAL
)
SELECT SDT
, EDT
, SMM
, EMM
, MM
, CEIL(MONTHS_BETWEEN (EDT+1, SDT)) MM2
, CEIL(MONTHS_BETWEEN (EDT, SDT)) MM3
, D1
, D2
, DD
, MM + ROUND (DD / 30) RESULT
, MM + CEIL (DD / 30) RESULT2
FROM (SELECT SDT
, EDT
, SMM
, EMM
, MONTHS_BETWEEN (EMM, SMM) MM
, (SMM - SDT) D1
, (EDT - EMM + 1) D2
, (SMM - SDT) + (EDT - EMM + 1) DD
FROM (SELECT SDT
, EDT
, TRUNC (ADD_MONTHS (SDT - 1, 1), 'MM') SMM
, TRUNC (EDT + 1, 'MM') EMM
FROM T))
1. 한달하고도 하루가 더 지났기 떄문에 2개월 이라면.
SELECT
CEIL
(
MONTHS_BETWEEN
(
TO_DATE('20050201', 'YYYYMMDD') + 1,
TO_DATE('20050101', 'YYYYMMDD')
)
) MOM
FROM DUAL
2. 날짜가 두달에 걸쳐서 있기 때문에 2개월이라면
SELECT
MONTHS_BETWEEN
(
TRUNC(TO_DATE('20050201', 'YYYYMMDD'),'MM'),
TRUNC(TO_DATE('20050131', 'YYYYMMDD'),'MM')
) + 1 MOM
FROM DUAL
=======================================================================================================
오라클의 MONTHS_BETWEEN과 비슷하게 처리한 예제
출처 : http://www.phpschool.com/gnuboard4/bbs/board.php?bo_table=tipntech&wr_id=60334&sca=%BD%BA%C5%A9%B8%B3%C6%AE&page=17
오라클의 add_months, months_between 함수를 자바스크립트로 만들일이 있어서 구현한 것입니다.
처음엔 만들기 귀찮아서.. 스쿨에서 비슷한 함수를 찾아봤는데 제가 못찾아서 그런건지 원래부터 없어서 그런건지 결국 못찾았습니다
간단히 코드 동작에 대해서 설명하자면....
add_months 함수의 경우
2008.01.31에 한달을 더하면 2008.02.29 가 나옵니다.
2008.04.30에 한달을 더하면 2008.05.31 이 나오고요
한달 더 한다고 단순히 기존 날짜에 30일을 더한 것이 아니라
마지막 날짜 여부까지 체크해줍니다.
months_between 함수의 경우
몇개월 차이인가 구하는 함수인데 여기저기 검색해보니
시작날짜, 종료날짜가 몇일인지 구한 후 단순히 30일로 나눠서 몇개월인지 구합니다.
이 경우 몇년 정도의 날짜 차이를 구하면 괜찮지만 몇십년 단위로
날짜 차이를 두면 당연히 몇개월의 오차가 생깁니다.(31일 날도 있어서)
그래서 이런 오차를 없애고자 1개월씩 더해서 루프 돌렸습니다 -_-
자세한 건 코드 보심 될듯싶습니다.
<script language="javascript" type="text/javascript">
/*
오라클의 개월수 더하는 함수와 동일
ex) add_months('2008.04.04',10);
*/
function add_months(pdate, diff_m) {
var add_m;
var lastDay; // 마지막 날(30,31..)
var pyear, pmonth, pday;
pdate = makeDateFormat(pdate); // javascript 날짜형변수로 변환
if (pdate == "") return "";
pyear = pdate.getYear();
pmonth= pdate.getMonth() + 1;
pday = pdate.getDate();
add_m = new Date(pyear, pmonth + diff_m, 1); // 더해진 달의 첫날로 셋팅
lastDay = new Date(pyear, pmonth, 0).getDate(); // 현재월의 마지막 날짜를 가져온다.
if (lastDay == pday) { // 현재월의 마지막 일자라면 더해진 월도 마지막 일자로
pday = new Date(add_m.getYear(), add_m.getMonth(), 0).getDate();
}
add_m = new Date(add_m.getYear(), add_m.getMonth()-1, pday);
return add_m;
}
/*
오라클의 개월수 차이 구하는 함수와 동일
ex) months_between('20080404','20060101');
*/
function months_between(edate, sdate) {
var syear, smonth, sday;
var eyear, emonth, eday;
var diff_month = 1;
sdate = makeDateFormat(sdate); // javascript 날짜형변수로 변환
edate = makeDateFormat(edate); // javascript 날짜형변수로 변환
if (sdate == "") return "";
if (edate == "") return "";
syear = sdate.getYear();
eyear = edate.getYear();
smonth= sdate.getMonth() + 1;
emonth= edate.getMonth() + 1;
sday = sdate.getDate();
eday = edate.getDate();
while (sdate < edate) { // 한달씩 더해서 몇개월 차이 생기는지 검사
sdate = new Date(syear, smonth - 1 + diff_month, 0);
diff_month++;
}
if (sday > eday) diff_month--;
diff_month = diff_month - 2;
return diff_month;
}
/* yyyymmdd, yyyy-mm-dd, yyyy.mm.dd 를 javascript 날짜형 변수로 변환 */
function makeDateFormat(pdate) {
var yy, mm, dd, yymmdd;
var ar;
if (pdate.indexOf(".") > -1) { // yyyy.mm.dd
ar = pdate.split(".");
yy = ar[0];
mm = ar[1];
dd = ar[2];
if (mm < 10) mm = "0" + mm;
if (dd < 10) dd = "0" + dd;
} else if (pdate.indexOf("-") > -1) {// yyyy-mm-dd
ar = pdate.split("-");
yy = ar[0];
mm = ar[1];
dd = ar[2];
if (mm < 10) mm = "0" + mm;
if (dd < 10) dd = "0" + dd;
} else if (pdate.length == 8) {
yy = pdate.substr(0,4);
mm = pdate.substr(4,2);
dd = pdate.substr(6,2);
}
yymmdd = yy+"/"+mm+"/"+dd;
yymmdd = new Date(yymmdd);
if (isNaN(yymmdd)) {
return false;
}
return yymmdd;
}
// 4월30일에 1개월 더하기 => 5월31일
alert(add_months('2008.04.30',1));
// 몇개월 차이인지 구하기 => 1104 개월 차이
alert(months_between('2100.01.01','2008.01.01'));
</script>























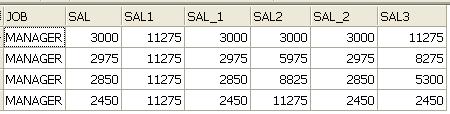
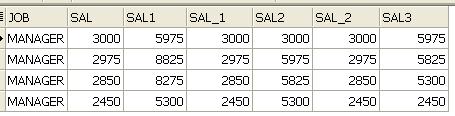
 Oracle 10g SQL MODEL Clase.pdf
Oracle 10g SQL MODEL Clase.pdf
1. 한달하고도 하루가 더 지났기 떄문에 2개월 이라면.
SELECT
CEIL
(
MONTHS_BETWEEN
(
TO_DATE('20050201', 'YYYYMMDD') + 1,
TO_DATE('20050101', 'YYYYMMDD')
)
) MOM
FROM DUAL
2. 날짜가 두달에 걸쳐서 있기 때문에 2개월이라면
SELECT
MONTHS_BETWEEN
(
TRUNC(TO_DATE('20050201', 'YYYYMMDD'),'MM'),
TRUNC(TO_DATE('20050131', 'YYYYMMDD'),'MM')
) + 1 MOM
FROM DUAL