1. Cursor 사용하기
|
DECLARE |
2. Cursor 사용하지 않고 Loop
| BEGIN FOR CUR1 IN (SELECT CASINO_BUSN_DATE, SFT_NO FROM CSM_WORK_ORG_DTL_TBL) LOOP DBMS_OUTPUT.PUT_LINE(CUR1.CASINO_BUSN_DATE || CUR1.SFT_NO); END LOOP; END; / |
1. Cursor 사용하기
|
DECLARE |
2. Cursor 사용하지 않고 Loop
| BEGIN FOR CUR1 IN (SELECT CASINO_BUSN_DATE, SFT_NO FROM CSM_WORK_ORG_DTL_TBL) LOOP DBMS_OUTPUT.PUT_LINE(CUR1.CASINO_BUSN_DATE || CUR1.SFT_NO); END LOOP; END; / |
출처 : http://scidb.tistory.com/30
기획팀에서 이대리가 전산실에 와서 부탁을 한다.
기획실 이대리:"월별 부서별로 2002년도 실적을 좀 뽑아주실수 있나요?"
전산실 김대리:"네 오늘저녁 6시쯤 오시면 실적 보고서를 드릴수 있습니다."
기획실 이대리:"실적을 만드실때 주의사항이 있습니다.
월별 부서별로 실적을 뽑을때 만약 20번 부서에서 5월, 7월에
실적이 없다고 하더라고 5월,7월 실적을 0 으로 표시해주세요."
전산실 김대리:"네 알겠습니다. 그것은 별로 어렵지 않습니다."
년월만 들어있는 테이블과 월별부서별실적 테이블의 구조는 아래와 같다.
월별 부서별 실적테이블의 2002년 실적은 다음 그림과 같다.
모든 월에 실적이 있는것은 아니다.(예를 들면 10번 부서는 2002년도에 1,3,6,7,8,10,11 월에 실적이 없다. )
30번 부서부터는 지면관계상 그림에서 생략하였다.
기획실 이대리의 요구사항은 아래그림과 같다.
(실적이 없는달은 실적을 0 으로 표시함)
30번 부서의 실적부터는 지면관계상 그림에서 생략하였다.
다행히 월별, 부서별 실적 테이블이 존재하기 때문에 김대리는 묵묵히 월별 실적 SQL을 아래처럼 작성하였다.
아래처럼 작성한 이유는 부서가 20개(10번부터 200번까지) 있기 때문에 부서별로 무조건 12건(1월~12월)을 만들기 위해서 이다.
SELECT e.deptno, m.yymm, NVL(e.sale_amt,0)
FROM year_month m , dept_sale_history e
WHERE m.yymm = e.yymm(+)
AND e.DEPTNO(+) = 10 --> 10번부서에 대해서 1월~12월 실적을 만듬.
AND m.yymm like '2002%'
Union all
SELECT e.deptno, m.yymm, NVL(e.sale_amt,0)
FROM year_month m , dept_sale_history e
WHERE m.yymm = e.yymm(+)
AND e.DEPTNO(+) = 20 --> 20번부서에 대해서 1월~12월 실적을 만듬.
AND m.yymm like '2002%'
Union all
SELECT e.deptno, m.yymm, NVL(e.sale_amt,0)
FROM year_month m , dept_sale_history e
WHERE m.yymm = e.yymm(+)
AND e.DEPTNO(+) = 30 --> 30번부서에 대해서 1월~12월 실적을 만듬.
AND m.yymm like '2002%'
Union all
...........................................................................................중간생략
Union all
SELECT e.deptno, m.yymm, NVL(e.sale_amt,0)
FROM year_month m , dept_sale_history e
WHERE m.yymm = e.yymm(+)
AND e.DEPTNO(+) = 200 --> 200번부서에 대해서 1월~12월 실적을 만듬.
AND m.yymm like '2002%'
우연히 김대리의 작업을 지켜보던 전산실 박과장이 한마디 한다.
전산실 박과장 :"김대리 그작업할때 200번이나 노가다(Union All) 할생각이냐?
"SQL 공부좀해라"
김대리에게 호통을 친 박과장은 자신감 있게 아래의 SQL을 1분만에 만들었다.
위의 SQL 의 핵심은 모든 부서에 대하여 1월~12월 까지 와꾸?(틀)를 만들어 놓고
부서별 월별실적 테이블과 아우터 조인을 하기위해서 이다.
위의 SQL 에서 EXISTS 를 사용한 이유는 2002 년도에 실적이 있는 부서만 뽑기 위해서다.
하지만 위의 SQL 도 비효율이 있다.
부서별 월별 실적테이블을 2번이나 ACCESS 하였다.
박과장의 작업을 옆에서 지켜보던 신입사원이 고개를 기우뚱 하며 박과장에게 말을 건낸다.
전산실 신입사원:"dept_sale_history" 테이블을 2번 사용하지 않고도 같은 실적을 뽑을수 있습니다."
전산실 박과장 :"그래? 그럼 한번해봐"
신입사원을 지켜보던 박과장은 경악을 금치 못한다.
신입사원이 20초만에 SQL 을 작성하고도 성능은 신입사원의 SQL이 우수했기 때문이다.
단 4줄의 SQL 로 기획팀 이대리의 요구사항을 해결하였다.
박과장은 SQL 을 사용한지 10년이 넘는 배테랑 개발자 이지만 10g 신기능은 써보지 못한 상태였다.
아래의 SQL이 신입사원의 SQL 이다.
신입사원이 위의 SQL 을 사용할수 있었던건 처음 배운 SQL 문법이 Oracle 10g 기준이었고
박과장은 Oracle 8 버젼의 SQL을 공부 해었기 때문이다.
위의 Partition Outer Join 은 10g 의 새기능이다.
Partition Outer Join 의 기능을 요약하면 부서별로 중간중에 빠진 월의 실적을 생성해주는 기능이다.
결론 :
Partition Outer Join 은 10g 의 신기능중 일부에 불과하다.
버전별로 New Features의 중요성을 다시한번 강조하지만 위의 경우와 같이
신기능을 모르면 작업량이 늘어날수 밖에 없고 대부분 성능도 느리다.
또한 Oracle 8.0 시절에 최적화된 SQL 이 항상 Oracle 10g 에서 최적화된 SQL 이라고 볼수 없다.
Oracle 9i 가 나온지는 10년이 됬으며 Oralce 10g 가 나온지도 6년이 지났고 2년전에 Oracle 11g 가 나왔다.
신버젼이 나올때 마다 알라딘의 요술램프처럼 주인님이 사용해주기를 기다리는 마술 같은 여러가지 신기능이 숨어있다는 점을 기억하자.
===========================================================================================
===========================================================================================
출처 : http://ukja.tistory.com/361
데이터 모델링을 하다보면 비정규화의 유혹에 빠지는 경우가 있습니다. 이유는 여러가지가 있겠지만, 대표적인 한가지 이유는 우리의 데이터 인식법과 관계형 데이터베이스의 표현 양식에서 차이가 있다는 것입니다. 가령 특정 테이블에 있는 인덱스별로 컬럼 목록을 보고 싶다면, 우리 눈에는 이렇게 보는 것이 가장 편합니다.
| T1_N1 C1, C2, C3 T1_N2 C3 T1_N3 C2, C1 |
하지만 관계형 데이터베이스는 정규화 법칙에 의해 다음과 같이 데이터를 저장하게 됩니다. 보기가 어렵죠.
| T1_N1 C1 T1_N1 C2 T1_N1 C3 T1_N2 C3 T1_N3 C2 T1_N3 C1 |
정규화된 형태에서 데이터를 추출하면 우리가 데이터를 인식하는 방법과 달라서 대단히 불편하게 느끼게 됩니다. 이런 이유 때문에 비정규화의 유혹이 생길 수 있습니다. (엄격하게 말하면 위의 예는 제 1 정규형에 해당합니다)
즉 비정규화란 "우리가 데이터를 인식하는 방식 그대로" 표현하고자 하는 욕구를 의미한다고 할 수 있습니다. 비정규화를 하면 쿼리가 간단해지는 것도 이런 이유 때문입니다. 더 정확하게 말하면 우리 눈에 간단해보이는거죠. 물론 성능을 위한 적절한 비정규화는 삶의 양념같은 역할을 하기도 합니다. 너무 빡빡한 삶은 재미가 없잖아요? ^^;
다행스러운 것은 오라클이 제공하는 (비교적 최신의) 기능들을 잘 이용하면 관계형으로 저장된 데이터를 비교적 간단하게 우리가 원하는 비정규화된 형태로 추출할 수 있다는 것입니다.
간단한 예제를 볼텐데요, 우선 다음과 같이 테이블 T1과 총 6개의 인덱스(Primary Key 포함)을 만듭니다.
|
create table t1( create index t1_n1 on t1(c1, c2); |
우리의 목적은 다음과 같은 표 형태로 인덱스별, 컬럼별 순서와 Unique 여부를 보는 것입니다. U가 붙으면 Unique이고, T1_N4의 경우에는 (C3, C1, C2)로 이루어져 있다는 의미입니다.
| Index_name C1 C2 C3 C4 ----------- -- -- -- -- SYS_C0016792 1U T1_N1 1 2 T1_N2 1 2 T1_N3 1 T1_N4 2 3 1 T1_N5 1 2 3 |
위의 같은 표현 양식에는 일반적으로 표현하기 힘든 두 가지 쿼리 패턴이 숨어 있습니다.
위의 두 가지 요구 사항은 매우 보편적으로 발생합니다. 최신 버전의 오라클에서는 Partition Outer Join과 Listagg 함수를 이용하면 비교적 간단하게 구현할 수 있습니다. 그렇지 않다면 좀 더 수고스러운 과정을 거쳐야할 것이구요.
우선 Missing Value를 채우는 가장 보편적인 방법은 값을 중복해서 복사하는 것입니다. 가령 다음과 같이 인덱스별, 컬럼별로 모든 조합이 다 나오도록 중복된 데이터 셋을 만들면 됩니다.
| INDEX_NAME COLUMN_NAME -------------------- -------------------- SYS_C0016792 C1 SYS_C0016792 C2 SYS_C0016792 C3 SYS_C0016792 C4 T1_N1 C1 T1_N1 C2 T1_N1 C3 T1_N1 C4 T1_N2 C1 T1_N2 C2 T1_N2 C3 T1_N2 C4 T1_N3 C1 T1_N3 C2 T1_N3 C3 T1_N3 C4 T1_N4 C1 T1_N4 C2 T1_N4 C3 T1_N4 C4 T1_N5 C1 T1_N5 C2 T1_N5 C3 T1_N5 C4 |
위와 같은 형태의 데이터를 만드는 가장 보편적인 방법은 복사를 위한 피봇(Pivot) 테이블을 이용하는 것입니다. 아래와 같이 DBA_TAB_COLUMNS 뷰를 피봇 테이블로 활용할 수 있습니다. DBA_TAB_COLUMNS와 DBA_INDEXES 뷰는 정상적인 조인이 불가능합니다. DBA_INDEXES 뷰에는 컬럼 정보가 없기 때문입니다. 따라서 Cartesian Join이 발생하게 되고 그로 인해 인덱스별로 컬럼 수만큼 복사가 발생하게 됩니다.
|
-- pivot table -- 그 덕분에 다음과 같이 복사가 이루어짐 |
Missing Value를 채운 후, 그 데이터를 DBA_IND_COLUMNS 뷰와 조인하면 우리가 원하는 완전한 형태의 정보를 얻을 수 있습니다.
|
select INDEX_NAME I COLUMN_NAME COLUMN_ID COLUMN_POSITION |
이제 남은 일은 Row로 존재하는 데이터를 Column 형태로 표현하는 것입니다. 아래와 같이 DECODE 함수와 MAX 함수를 조합하면 완전한 형태의 피보팅(Pivoting)이 이루어집니다.
|
-- pivoting and decode
|
Oracle 11gR2에서는 LISTAGG 함수를 이용하면 훨씬 간단한 방법으로 구현할 수 있습니다. 그 이전 버전이라면 XMLAGG 함수를 사용할 수 있을 것입니다.
|
-- pivoting and listagg INDEX_NAME COL_LIST |
Partition Outer Join을 사용하면 Cartesian Join을 사용할 필요없이 훨씬 효율적으로 Missing Value를 채울 수 있습니다.
아래 결과를 보면 DBA_TAB_COLUMNS 뷰와 DBA_IND_COLUMNS 뷰를 Outer Join하는 것만으로 Missing Value를 채울 수가 없다는 것을 알 수 있습니다.
|
-- what is partition outer join? INDEX_NAME COLUMN_NAME COLUMN_POSITION |
하지만 다음과 같이 Partition Outer Join을 사용하면 DBA_IND_COLUMNS.INDEX_NAME 별로 그룹핑해서 Outer Join을 수행합니다. 따라서 Missing Value를 완벽하게 채울 수 있습니다.
|
select
|
위에서 얻은 결과를 LISTAGG 함수를 이용하면 원하던 포맷의 결과를 얻을 수 있습니다.
|
-- partition outer join & listagg INDEX_NAME COL_LIST |
적다보니 너무 길어졌네요. 오라클이 제공하는 기능을 잘 이용하면 그다지 어렵지 않게(?) 정규화된 관계 모델로부터 우리가 인식하는 형식의 데이터로 표현할 수 있다는 정도의 의도로 봐주시면 되겠습니다.
===========================================================================================
===========================================================================================
출처 : http://blog.naver.com/savemyface/130020495511
Oracle 10g SQL의 개선 사항 중, 보고서 작성에 유용한 기능을 한가지 알아봅니다.
Partitioned Outer Join은 기존의 Outer Join을 개선한 것으로서, OLAP 환경의 Dimension 테이블과 Fact 테이블을 조인하는 경우, 유용하게 사용 할 수 있습니다.
구체적인 설명 보다는 간단한 예를 들어 살펴보겠습니다.
times 테이블에는 2006년도 1월~12월의 시계열 데이터가 포함되어 있습니다.
SQL> create table times
2 (year number,
3 month number);
테이블이 생성되었습니다.
SQL>
SQL> insert into times(year, month)
2 select 2006, rownum from all_objects where rownum <=12;
12 개의 행이 만들어졌습니다.
SQL>
SQL> select * from times;
YEAR MONTH
---------- ----------
2006 1
2006 2
2006 3
2006 4
2006 5
2006 6
2006 7
2006 8
2006 9
2006 10
2006 11
2006 12
12 개의 행이 선택되었습니다.
sales 테이블에는 년도 및 월별 제품 판매량 데이터가 포함되어 있습니다.
SQL> create table sales
2 (year number,
3 month number,
4 prod varchar2(10),
5 quantity number);
테이블이 생성되었습니다.
SQL> insert into sales values(2006, 1, 'PS3', 25);
SQL> insert into sales values(2006, 5, 'PS3', 32);
SQL> insert into sales values(2006, 5, 'X-box', 54);
SQL> insert into sales values(2006, 6, 'PS3', 21);
SQL> insert into sales values(2006, 6, 'X-box', 67);
SQL> insert into sales values(2006, 7, 'PS3', 21);
SQL> insert into sales values(2006, 7, 'X-box', 26);
SQL> insert into sales values(2006, 8, 'X-box', 15);
SQL> insert into sales values(2006, 11, 'PS3', 27);
SQL> insert into sales values(2006, 12, 'PS3', 25);
SQL> insert into sales values(2006, 12, 'X-box', 15);
SQL> select * from sales
2 order by prod, year, month, quantity;
YEAR MONTH PROD QUANTITY
---------- ---------- ---------- ----------
2006 1 PS3 25
2006 5 PS3 32
2006 6 PS3 21
2006 7 PS3 21
2006 11 PS3 27
2006 12 PS3 25
2006 5 X-box 54
2006 6 X-box 67
2006 7 X-box 26
2006 8 X-box 15
2006 12 X-box 15
11 개의 행이 선택되었습니다.
작성하고자하는 결과 형식은 다음과 같습니다.
즉, 빨간색으로 표시된 행은 해당 년도 및 월에 해당 제품의 판매량이 존재하지 않음을 의미합니다.
예를 들어, PS3는 2006년도 2월에 판매량이 전혀 없음을 나타냅니다.
제품명 년도 월 수량
---------- ---------- ---------- ----------
PS3 2006 1 25
PS3 2006 2
PS3 2006 3
PS3 2006 4
PS3 2006 5 32
PS3 2006 6 21
PS3 2006 7 21
PS3 2006 8
PS3 2006 9
PS3 2006 10
PS3 2006 11 27
PS3 2006 12 25
X-box 2006 1
X-box 2006 2
X-box 2006 3
X-box 2006 4
X-box 2006 5 54
X-box 2006 6 67
X-box 2006 7 26
X-box 2006 8 15
X-box 2006 9
X-box 2006 10
X-box 2006 11
X-box 2006 12 15
이런 결과를 만들기 위해서는 sales 테이블을 prod 컬럼의 종류에 따라 파티션하고,
각 파티션을 times 테이블과 outer join을 수행해야합니다.
이를 위해서, Oracle 10g 부터는 손쉽게 사용 할 수 있는 Partitioned Outer Join을 소개하였습니다.
SQL> select s.prod, t.year, t.month, s.quantity
2 from sales s partition by (s.prod)
3 right outer join times t
4 on s.year=t.year and s.month=t.month;
PROD YEAR MONTH QUANTITY
---------- ---------- ---------- ----------
PS3 2006 1 25
PS3 2006 2
PS3 2006 3
PS3 2006 4
PS3 2006 5 32
PS3 2006 6 21
PS3 2006 7 21
PS3 2006 8
PS3 2006 9
PS3 2006 10
PS3 2006 11 27
PS3 2006 12 25
X-box 2006 1
X-box 2006 2
X-box 2006 3
X-box 2006 4
X-box 2006 5 54
X-box 2006 6 67
X-box 2006 7 26
X-box 2006 8 15
X-box 2006 9
X-box 2006 10
X-box 2006 11
X-box 2006 12 15
24 개의 행이 선택되었습니다.
출처 : http://majesty76.tistory.com/64
redo log file이 3개 있다. 이후 강제 log switch가 일어나거나, 혹은 자동으로 log switch가 일어나 redo log file이 3번까지 가득 찼다. 그러면 다음 log는 다시 첫번째 redo log file에 덮어 씌워질 것이고, 그렇게 되면 처음 기록된 log는 나중에 기록된 log에 의해 삭제 될 것이다. 이런 경우 datafile을 백업 받고, 언젠가 datafile이 손상 되었을 때, 백업 datafile을 이용 하려는 경우 SCN이 일치하지 않아 redo log file에 모든 로그 기록을 보고 SCN을 일치 시켜야 하는데, 앞서 기록된 log가 덮어 쓴 log로 인해 삭제 되어서 그때의 SCN번호를 매길 때 어떤 작업이 일어났는지 알 수 없기 때문에 database를 올릴 수 없게 된다. (no archive mode)
이와 같은 현상을 방지 하기 위하여 등장 한 것이 Archive file(아카이브 파일)이다. archive file은 redo log file이 가득 찼을 때, 처음 file에 덮어 쓰기 전에 archiver 백그라운드 프로세스를 통해 처음 redo log file을 archive file에 저장한다. 이로 인해 log 기록들이 저장되어 복구를 손실 없이 좀더 안전하게 할 수 있는 것이다.
그렇다고 꼭 장점만 있는 것은 아니다. archive file은 용량을 많이 차지 할 뿐더러, 만약 archive 저장 디렉토리가 가득 찼는데(사실 금방 찬다고 한다) redo log file을 archive에 내려 써야 할 차례가 오면, archive file에 빈 공간이 생길 때까지 archiver 백그라운드 프로세스는 동작하지 않는다. 그러면 LGWR 백그라운드 프로세스 역시 동작하지 않을 것이고, 결국 이렇게 되면 DB가 죽어버리는 현상이 나타난다(archive hang 현상).
혹은 archive 지정 디렉토리가 oracle을 설치한 계정인지도 살펴봐야 한다. 만약 root로 되어 있다면 archiver가 저장을 하지 못해 DB가 죽는 경우도 생길 수 있다.
조심해야 할 점을 기억하며 DB를 archive mode로 바꾸어 보자.(필자는 pfile로 작업할 것이다)
우선 DB를 내린 후 터미널 창이 나오게 한다.
SQL> shutdown immediate
SQL> exit

archive file이 들어갈 디렉토리 2개를 만들어 준다.
oracle]$ mkdir -p /app/archdata/arch01
oracle]$ mkdir -p /app/archdata/arch02

pfile(inittestdb.ora)를 수정하기 위해 pfile이 있는 디렉토리로 가서 init[instance명].ora 파일을 vi editor로 연다.
oracle]$ cd /app/product/10g/dbs
oracle]$ vi inittestdb.ora

pfile(inittestdb.ora) 맨 아래부분에 추가해 준다. (파일 형태가 %s_%t_%r.arc로 만들어 질 것이다.)
*.log_archive_dest_1='location=/app/archdata/arch01'
*.log_archive_dest_2='location=/app/archdata/arch02'
log_archive_format=%s_%t_%r.arc

다시 sys 계정으로 접속하여 no archive mode인지 확인 해 보자.
SQL> startup mount
SQL> archive log list (no archive mode 확인)

archive mode로 바꾸어 주자. 그리고 DB를 open한다.
SQL> alter database archivelog;
SQL> alter database open;

archive mode로 바뀌었는지 확인 한다.
SQL>archive log list

redo log file의 log들이 archive file 에 모두 내려가도록 log switch를 여러번 수행한다.
SQL> alter system switch logfile; (여러번 수행)

log switch로 인해 archive file이 생성 되었는지 확인 한다. (터미널 창)
oracle]$ ls /app/archdata/arch02

다시 no archive 상태로 바꿔주자.
SQL> shutdown immediate
SQL> startup mount
SQL> alter database noarchivelog;

no archive mode로 변경 되었는지 확인 해 보자.
SQL>archive log list

Copyright 김도익 All rights reserved.
테이블 이력(관련 테이블) 저장시 일련번호(Sequence) Trigger로 부여하기
샘플
|
CREATE TABLE TB_TEST1 ( CREATE TABLE TB_TEST2 ( CREATE SEQUENCE SQ_TB_TEST1 CREATE OR REPLACE TRIGGER TG_TEST1 CREATE OR REPLACE TRIGGER TB_TEST2 INSERT INTO TB_TEST1 VALUES (1, '한국'); SELECT * FROM TB_TEST1; SELECT * FROM TB_TEST2; UPDATE TB_TEST1 SET NM = '코리아' WHERE NUM = 1; SELECT * FROM TB_TEST1; SELECT * FROM TB_TEST2; |
TB_TEST2 의 IDX 값을 해당 NUM의 대한 일련번호를 사용할 경우에는 MAX를 사용해야 하나 FOR UPDATE를 사용하여 LOCK을 걸어야 하며 해당 ROW가 없을 경우에는 LOCK을 걸 수 없다.
그럴 경우 채번 테이블 생성하는 샘플을 보고 함수를 만들어 사용할 수 있다.
참고 : http://tyboss.tistory.com/entry/Oracle-채번-테이블-사용하여-채번하기-채번하기
|
ALTER TABLE TB_TEST1 ADD IDX NUMBER DEFAULT 0; |
위처럼 TB_TEST1에 IDX 컬럼을 추가한 후 참고 링크의 채번 테이블 처럼 사용하면 된다.
출처 : http://blog.naver.com/imdkkang/120087840004
참고 : http://database.sarang.net/?inc=read&aid=38554&criteria=oracle
| 데이터베이스의 존재 이유 중 하나는 수많은 사용자가 동시에 데이터에 접근, 수정하고 입력하는 작업을 수행하는 환경을 제공하는 데 있다. 자고로 많은 RDBMS 벤더에서 동시에 데이터에 접근하고 정합성을 보장하는 방법에 대해서 끊임없는 경쟁을 펼치고 새로운 방법을 내놓았다. 결국에는 많은 유저가 정합성을 보장하면서 데이터에 접근하는 환경을 제공하는 능력이 데이터 처리 능력과 트랜잭션 최대값으로 직결되고, 이것이 곧 각 RDBMS의 우열을 가르는 잣대라고 봐도 과언이 아니다. 이 글에서는 오라클 데이터베이스를 중심으로 LOCKING 메커니즘에 대해 설명한다. |
<그림 1>과 같이 동시 유저수가 많을수록 트랜잭션 개수는 일정 수준 이상이 되면 줄어들고 정합성과 동시성 관계 역시나 반비례 관계에 있다. 데이터의 일관성을 높이기 위해서는 반드시 락(LOCK)을 사용해야 하지만, 동시성을 높이기 위해서는 락의 사용을 최소화해야 한다는 점에서 이 둘의 관계 제어(CON CURRENCY CONTROL)가 상당히 힘든 일임을 알 수 있다. 따라서 이번 글을 통해 동시성 제어를 향상시킬 수 있는 방법에 대해 알아보기로 하겠다.

<그림 1> 동시성과 정합성 관계
동시성 향상의 방법
LOST UPDATE 방지
① A 유저가 데이터를 조회한다.
② B 유저가 같은 로우를 조회한다.
③ A 유저가 애플리케이션을 통해 로우를 업데이트하고 COMMIT을 수행한다.
④ B 유저가 같은 로우를 업데이트한다.
결국은 A 유저가 업데이트한 데이터는 B 유저에 의해 오버라이트되어 버린다. 따라서 A가 수정한 데이터는 잃어버리게 된다. 이것이 전형적인 LOST UPDATE의 예이다. 이러한 오라클의 SELECT에 대한 non-blocking의 특성(select에 락모드가 null)으로 인한 세션에서의 LOST UPDATE를 방지하기 위해 정합성이 중시되는 프로그램 작성 시에 SELECT를 수행하는 로우에 SELECT FOR UPDATE 문을 사용해 명시적으로 락을 걸어주고 해당 로우에 대해 데이터 수정을 하는 경우가 많다.
그러나 이러한 Pessimistic Lock을 설정한 후 락의 보유 시간이 길거나 중간에 수행되는 로직이 복잡하면 해당 데이터를 동시에 변경하는 유저수가 늘어나고 늘어날수록 동시성은 떨어지게 된다. 물론 FOR UPDATE 문에 nowait , wiat n [second]와 같은 옵션이 존재해 대기시간을 조금 줄이는 효과를 낼 수 있지만 그리 큰 효과는 없을 것이다. 현장 애플리케이션 개발에서 오라클 locking 메커니즘을 제대로 이해하지 못하거나 믿지 못해 Pessmistic Locking을 과도하게 사용해 동시성이 저하되는 경우를 많이 목격했다.
그렇다면 Optimistic Locking만으로 동시성과 정합성이란 두 마리 토끼를 잡을 수는 없을까? 많은 방법들이 존재하지만 최적으로 꼽히는 방법 가운데 tomas kyte의 asktom 사이트에서도 수차례 언급했던 글을 토대로 방법을 알아보기로 하자.
Version 컬럼과 Pseudo 컬럼을 이용한 체크
그렇다면 일반적인 UPDATE 문, 즉 Optimistic Lock만으로 동시성을 확보하면서 여러 사용자가 동일한 데이터를 수정하더라도 정합성을 보장하는 방법에 무엇이 있는지를 살펴보도록 하자.
● Version 필드를 통한 체크
첫 번째 방법은 변경하는 테이블에 변경시간을 기록하는 컬럼을 추가하는 것이다. <리스트 1>은 DEPT 테이블에 last_mod라는 timestamp 형식의 컬럼을 추가해 SELECT FOR UPDATE로써 레코드 락을 걸지 않고 변경 컬럼 값만을 체크해 해당 컬럼이 변경되었다면 update되지 않도록 수행하는 처리 절차를 구사한 예이다. 이 방법은 명시적인 락을 걸지 않고도 정합성을 유지할 수 있다.

● Pseudo 컬럼을 이용한 변경 체크
앞의 변경 컬럼을 사용하는 것은 추가적인 테이블 변경 작업을 수반하기 때문에 사용할 수 없는 테이블이 수정 불가능한 환경에서는 부적합할 수도 있다. 여기서 기존의 테이블에 컬럼 추가 없이 Pseudo 컬럼을 이용한 방법을 사용할 수 있다.
이는 10g에서의 SCN 번호를 가져올 수 있는 ORA_ROWSCN 함수를 사용해서 체크하는 방법을 이용하면 간단히 구현될 수 있다. 10g에서는 SCN 값의 변경사항 중 하나가 종래의 block level SCN에서 Row level SCN을 지원하게 되었다는 것이다(SCN은 System Change Number 또는 System Commit Number라고 병행해서 사용된다. 이 값은 커밋시마다 부여되는 오라클의 내부시계와 같은 역할을 수행한다).

기존에 BLOCK 레벨로 부여하던 SCN 값이 로우 레벨에 따라 다른 번호를 가질 수 있게 된 것이다. 따라서 이러한 ora_ rowscn 값을 이용해 테이블의 로우가 언제 변경되었는지에 대한 정보도 뽑아볼 수 있다. 그러나 모든 테이블에 다 적용되는 것이 아닌 ROW LEVEL SCN을 적용하게끔 테이블 생성시 ROWDEPENDENCIES 옵션으로 생성해야 한다는 것이다.
UPDATE 여부 확인
|
CREATE TABLE T_LOCK ( INSERT INTO T_LOCK (ID) VALUES (1); COMMIT; INSERT INTO T_LOCK (ID) VALUES (2); COMMIT; SELECT ID SELECT TABLE_NAME |
SEQUENCE와 채번 테이블을 이용한 동시성 향상
일반적으로 해당 테이블의 최대값을 읽어와서 INSERT를 수행하는 경우에 동시에 많은 유저가 수행된다면 PK 중복에러가 발생할 여지가 크다. 따라서 일반적으로 max 값을 읽어오는 select되는 시점에서 for update 문을 사용해 해당 레코드에 락을 거는 방법을 사용한다. 그러나 역으로는 동시성이 저하되는 부작용이 나타난다.

<그림 2> 다른 세션에서 최대값을 획득한 후 입력 시 에러 발생
● SEQUENCE 객체의 사용
단순 일련번호로 PK가 구성되어 있다면 시퀀스의 경우에는 동시다발적으로 여러 명의 유저가 시퀀스를 부여 받더라도 절대 중복이 발생하지 않는다. 중복 방지에만 초점을 맞춘다면 적합할지 모르지만 CACHE 값만큼 메모리에 고정(keeping)되어 있는 경우 데이터베이스 서버의 갑작스런 다운시나 메모리 영역에서 ageout되어 다음에 시퀀스를 발행할 경우 이전에 caching되어 있는 시퀀스의 수만큼 중간을 건너뛰고 발행될 수도 있다. 따라서 일련번호가 타이트하게 관리되어야 할 필요성이 있다면 적합하지 않다.
● 채번 테이블의 이용
시퀀스를 사용할 수 없는 특수한 환경에서는 채번 테이블을 사용하는 경우 동시 유저에 의해 채번 테이블이 사용될 수 있다. 다만 채번 테이블의 경우에는 여러 명이 동시에 접근할 경우 해당되는 채번테이블이 UPDATE 되는 경합을 유의해야 한다.

● 시퀀스를 이용한 update 분산
<리스트 4>의 경우 동시다발적인 유저가 많다면 해당되는 상태인 데이터의 첫 번째 로우를 업데이트하는 LOCKING 부하가 집중되는 문제가 발생한다.

따라서 시퀀스의 최대값을 객체를 동시에 수정하는 최대 유저수만큼 생성한 후 <리스트 5>와 같은 쿼리로 수정하면 시퀀스의 수만큼 LOCKING이 분산되는 효과를 볼 수가 있다.

Deadlock의 방지
프로세스 A는 테이블 T1에 락을 걸고 있고 테이블 T2의 데이터를 변경하려 하며, 프로세스 B는 테이블 T2에 락을 걸고 있고 테이블 T1의 데이터를 변경하려는 상황에서 더 이상 진행되지 않고 HANG이 발생하는 경우가 여러분들이 잘 아는 전형적인 Deadlock이라고 할 수 있다. 오라클에서 Deadlock이 발생하면 뒤에 락을 획득한 쪽(프로세스B)이 실패해 모든 락을 해제하면서 에러가 발생하고 트랜잭션이 rollback된다.
수년간 데이터베이스 운영과 프로젝트를 수행했지만 이러한 데이터베이스 관리 시에 Deadlock은 굉장히 드물게 발생했다. 다만 신규로 개발된 프로시저나 애플리케이션의 단일 테이블에서 일반적으로 아주 드물게 발생하는 경우가 있고 오라클에서도 자체적으로 발생하는 경우보다는 애플리케이션 설계상의 문제로 발생되는 경우가 많다. 특히 데이터베이스 애플리케이션뿐만 아니라 자바의 synchronized 등의 다양한 상황에서 만날 수 있는 경우가 많다. 프로젝트 초기에 이러한 Deadlock의 상황을 만난다면 원인을 찾아내기가 상당히 까다로운 게 사실이다. 그렇다면 이러한 Deadlock을 방지하는 방법에는 어떤 것들이 있을까?

<그림 3> Deadlock의 도식화
|
오라클의 락(Lock) 종류 | ||||||||||||
|
오라클에서는 락의 종류가 크게 세 가지로 구분된다.
|
● INITRANS의 추가
동일 블록 당 진행할 수 있는 트랜잭션의 개수를 지정하는 옵션인 INTRANS 값이 부족하면 Deadlock이 발생할 수 있다. 이 값이 부족하면 서로 다른 트랜잭션이 각기 동일 테이블의 각기 다른 데이터를 수정하더라도 그 데이터가 동일 블록에 위치한다면 Deadlock이 발생할 수 있다. 따라서 하나의 테이블에 대해 퍼포먼스 등의 이유로 동시에 다른 데이터를 처리하는 트랜잭션을 수행하고자 한다면, 테이블의 INTRANS 값을 크게 해서, 하나의 블록에 여러 개의 트랙잭션이 DML 처리를 수행하더라도 공간이 부족해서 기다리는 상황은 없도록 해야 한다.
● 적은 블록 사이즈와 블록당 적은 데이터
너무 큰 블록 사이즈(표준 블록 사이즈 8K보다 큰)를 사용한다거나 하나의 블록에 많은 데이터가 들어 있다면 BLOCK LEVEL 락이 발생할 가능성이 크다. 따라서 pctfree를 약간 크게 잡음으로써 의도적으로 블록 당 로우수를 줄이는 방법도 그 대안이 될 수 있다. 될 수 있으면 표준 블록사이즈를 사용하거나 필요하다면 오라클의 멀티블록 사이즈를 이용해 2K, 4K 적은 블록 사이즈의 이용을 고려해본다.
>> 각주:PCTFREE: 업데이트 시 사이즈가 늘어날 것을 대비한 BLOCK의 여유공간 비율. 일반적으로 10%. 이 값을 크게 잡는다면 블록당 들어가는 로우 사이즈는 줄어들 것이다.
● 해당 테이블에 적절한 인덱스의 존재 여부 확인
오라클 데이터베이스에는 해당되지 않지만 SQL 서버의 경우에는 INDEX SCAN이 아닐 경우 Lock escalation(락의 확대)울 수행해서 테이블 락으로 확대해 버린다. 오라클은 Lock escalation은 발생하지 않지만 FK, PK 관계의 부모 자식 테이블에서 부모 테이블의 로우를 삭제할 경우 인덱스가 없다면 자식 테이블 전체가 Shared Lock이 발생해버린다(이러한 사항은 8i 이전의 문제였고 Oracle 9i 이상이라면 FK에 INDEX가 존재하지 않아도 어떠한 락도 발생하지 않는 알고리즘으로 변화).
● 트랜잭션 처리의 최적화
SELECT FOR UPDATE로 LOCKING된 레코드의 처리에 너무 많은 로직이 들어간다거나 처리되는 DML 문이 최적화되지 못해 락의 보유시간이 길어지는 것을 방지해야 한다. 또한 정합성을 지나치게 중시해 과도하게 넓은 범위를 LOCKING하는 경우를 가능하면 줄이도록 한다.
● 애플리케이션 튜닝
업데이트와 관련된 싱글 스레딩으로 변경하는 것을 고려할 수 있다. 또한 업데이트 작업과 관련된 배치작업을 리스케줄링하는 것도 고려할 수 있다. 가능한 조치를 했음에도 불구하고 이러한 상황이 발생했다는 것은 제대로 된 애플리케이션 프로세스 모델링과 데이터베이스 모델링이 있지 않다는 증거이다. 가급적 이러한 상황을 막기 위해서는 무엇보다도 업무단위에 대한 철저한 분석과 설계가 선행되어야 한다.
|
Deadlock 분석을 위한 팁 |
|
Deadlock이 발생한다면 alert.log에 해당 로그가 기록되지만 원인과 주체를 분석하기에는 정보가 부족한 것이 사실이다. 따라서 해당되는 Deadlock의 자세한 사항을 수집할 수 있도록 10027 이벤트를 추가적 으로 걸어줘서 해당주체를 분석할 수 있다. 레벨에 따라서 call stack, action, process state, SQL 문장 등의 정보를 획득할 수 있다. 다만 DBA 권한을 가진 유저만이 수행할 수 있다. 다음은 4 레벨로 call stack trace를 생성하게끔 수행한 예이다.
SQL>ALTER SYSTEM SET EVENTS‘ 10027 trace name context
|
● SELECT FOR UPDATE(비관적 잠금)의 동시성 증대
일반적으로 동시성 향상보다도 정합성에 초점을 두거나 LOST UPDATE를 방지하기 위한 목적으로 FOR UPDATE 옵션으로서 SELECT되는 해당 로우에 대한 잠금을 명시적으로 실행하는 방법을 많이 쓰고 있으리라고 생각된다. 그러나 이러한 명시적인 잠금은 잘 쓰면 정합성을 유지하는데 약이 되지만 잘못 쓸 경우 엄청난 동시성 저해 요소가 될 수 있다.
만일 다중 로우에 대한 락을 걸 때 한 건의 로우가 기존에 락이 걸린 상태면 전체가 잠금을 시도하는데 있어서 에러가 발생한다. 따라서 넓은 범위의 로우를 Locking하고 싶은 경우 이 한 건의 락이 해제될 때까지 기다려야 하는 상황이 발생한다.
리조트 예약시스템의 경우를 예로 들어보자. 단체 손님을 받아서 10층의 룸을 전부 락을 건 채 예약 작업을 시도한다고 가정하자. 그러나 옆의 다른 직원이 동일 층의 개인 손님 예약을 이미 락을 걸고 작업 중이면 앞의 직원은 Locking 작업은 실패할 것이며 이전 직원의 작업이 끝나기를 기다려야 할 것이다.
여기에 이러한 상황에 적합한 SELECT FOR UPDATE SKIP LOCKED라는 기존 Locking 범위를 Skip하는 추가적인 옵션이 존재한다. 이 방법은 9i부터 지원되는 undocumented된 방법이며 과거부터 메시지 처리를 위한 AQ(Advanced Queuing) 기능을 위해 존재했던 기능이기도 하다. 이 기능을 이용한 예제를 살펴보자.


<그림 4> SKIP LOCKED를 사용한 LOCK의 확대
유의해야 할 것은 이 기능은 Oracle 11g부터 정식으로 매뉴얼 상에 등장하는 기능이므로 이전 버전에서는 몇 가지 불안정한 면이 존재했다. 따라서 오라클 데이터베이스의 동시성 향상을 위한 예로서 소개한 기능이므로 실 환경에서의 적용보다는 테스트에 적용해 사용하길 바란다.
짧게나마 간단한 예제로서 동시성 제어와 관련된 사항과 이에 대한 방법론에 대해 살펴봤다. 동시성 제어는 매우 중요함에도 불구하고 프로젝트 수행 중에 만났던 많은 개발자들이 아직 많이 간과하는 부분이었다.
|
DBMS_LOCK을 이용한 사용자 정의 lock(User-defined lock) |
|
사용자가 임의로 특정 LOCK을 재현하기 위해서는 오브젝트 생성과 특정 트랜잭션이 필요하지만 DBMS_LOCK을 사용해 사용자 정의 lock을 구현할 수 있다.
- DBMS_LOCK.SLEEP(n) : n초 만큼 대기
|
필자소개
김도근 kilgw@naver.com|OracleAce, OCM, MCDBA ‘데이터베이스란 OS 위에 올라가 있는 애플리케이션에 불과하다' 라는 생각으로 항상 데이터베이스를 생각하면서 데이터베이스를 공부하는 것을 낙으로 삼고 있다. 스터디 및 온라인, 오프라인 기고 등의 활동을 전개 중이다.
출처 : 한국 마이크로 소프트웨어 [2009년 7월호]
=================================================================================================================
=================================================================================================================
출처 : http://www.gurubee.net/pages/viewpage.action?pageId=22904839
DBMS가 제공하는 Sequence 기능을 사용하는 것이 가장 좋으나, 이를 사용할 수 없는 경우 별도 구현해야 함
create table seq_tab ( gubun varchar2(1), seq number, constraint pk_seq_tab primary key(gubun, seq) ) organization index; create or replace function seq_nextval(l_gubun number) return number as pragma autonomous_transaction; -- 메인 트랜젝션에 영향을 주지 않고 서브 트랜젝션만 따로 커밋 l_new_seq seq_tab.seq%type; begin update seq_tab set seq = seq + 1 where gubun = l_gubun; select seq into l_new_seq from seq_tab where gubun = l_gubun; commit; return l_new_seq; end; /
begin update tab1 set col1 = :x where col2 = :y ; insert into tab2 values (seq_nextval(123), :x, :y, :z); loop -- do anything ... end loop; commit; exception when others then rollback; end; /
선분이력을 추가하고 갱신할 때 발생할 수 있는 동시성 이슈를 해결한 사례

declare cur_dt varchar2(14); begin select 고객ID from 부가서비스이력 where 고객ID = 1 and 종료일시 = to_date('99991231235959', 'yyyymmddhh24miss') for update nowait ; select 고객ID from 고객 where 고객ID = 1 for update nowait ; cur_dt := to_char(sysdate, 'yyyymmddhh24miss') ; -- ① update 부가서비스이력 -- ② set 종료일시 = to_date(:cur_dt, 'yyyymmddhh24miss') - 1/24/60/60 where 고객ID = 1 and 부가서비스ID = 'A' and 종료일시 = to_date('99991231235959', 'yyyymmddhh24miss') ; insert into 부가서비스이력(고객ID, 부가서비스ID, 시작일시, 종료일시) -- ③ values (1, 'A', to_date(:cur_dt, 'yyyymmddhh24miss'), to_date('99991231235959', 'yyyymmddhh24miss')) ; commit; -- ④ end;
출처 : http://inhim.blog.me/100101665843
채번 테이블을 사용하여 키값을 가져오는 방식은 추천할만한 방법은 아니다.
특히 키값이 건너뜀 없이 순차적으로 발행되어야 하는 업무요건이라면 채번 트랜잭션과 메인 트랜잭션이 분리될 수 없기 때문에 심한 Lock 경합을 피할 수 없을 것이다.
이런 업무요건은 heavy 한 동시트랜잭션 환경에서는 받아들일 수 없는 것이다.
키값이 건너뛰어 발행되도 괜찮다면 채번 트랜잭션은 메인 트랜잭션으로부터 분리하여 Lock 경합을 최소화하여야 한다.
아래의 방법은 간단한 자율트랜잭션 채번펑션을 이용해 이를 구현한 사례로서 "오라클 성능 고도화 원리와 해법 1(조시형 저)" 에서 발췌하였다.
이 사례에서 중요한 것은 채번펑션이 자율트랜잭션(autonomous_transaction) 이어야 한다는 것이다. 그렇지 않다면 메인트랜잭션의 일관성이 깨지게 될 것이기 때문이다.
예를 들어, 메인트랜잭션에서 8번 라인에서 에러를 만나 rollback 될 때에도 2번 라인의 update 문은 commit 될 것이기 때문이다.
하지만 채번펑션이 자율트랜잭션이라면 2번 라인의 update 문은 commit 되지 않을 것이므로 메인트랜잭션은 일관성을 지킬 수 있다.
채번 테이블 생성
| CREATE TABLE SEQ_TAB (GUBUN VARCHAR2 (3) , SEQ NUMBER , CONSTRAINT PK_SEQ_TAB PRIMARY KEY (GUBUN, SEQ) ) ORGANIZATION INDEX; |
ORGANIZATION INDEX 에 대한 설명 : http://blog.naver.com/tyboss/70151522617
채번 Function
|
CREATE OR REPLACE FUNCTION SEQ_NEXTVAL (L_GUBUN VARCHAR2) COMMIT; |
채번 Function 사용
|
BEGIN INSERT INTO TAB2 LOOP |
======================================================================================================
자율트랜잭션(autonomous transaction)이란 부모트랜잭션으로부터 독립적인 트랜잭션이라는 뜻으로서, 자율트랜잭션에 대해 더 알기 원한다면 아래 실습 결과를 보세요.
채번할 때 사용하는 COMMIT 때문에 PRAGMA AUTONOMOUS_TRANSACTION; 옵션을 사용하지 않은 경우에는 비지니스 로직의 ROLLBACK이 실행되지 않음
|
CREATE TABLE TAB_NONAUTO (MSG CLOB); CREATE TABLE TAB_AUTO (MSG CLOB); -- 1번 프로시저 생성 COMMIT; -- 2번 프로시저 생성 COMMIT; -- 테스트 SELECT * FROM TAB_NONAUTO; MSG --------------------------- 부모트랜잭션 입력 일반자식트랜잭션 입력
BEGIN
SELECT * FROM TAB_AUTO;
MSG --------------------------- 자율자식트랜잭션 입력
|
출처 : http://blog.naver.com/genezerg?Redirect=Log&logNo=20142202559
분석함수중에서 윈도우절(WINDOW절)을 사용할수 있는 함수를 윈도우함수라고 한다.
고로 분석함수중에서 일부만 윈도우절을 사용할수 있다는것이다.
PARTITION BY 절에 의해 명시된 그룹을 다시 그룹핑할수 있다.
윈도우 함수 종류
- AVG, COUNT, FIRST_VALUE, LAST_VALUE, MAX, MIN, STDDEV, SUM...
문법 > SUM(컬럼명) OVER(PARTITION BY [컬럼] ORDER BY [컬럼] [ASC/DESC]
ROWS / RANGE BETWEEN UNBOUNDED PRECEDING / PRECEDING / CURRENT ROW
AND UNBOUNDED FOLLOWING / CURRENT ROW)
ROW : 부분집합인 윈도우 크기를 물리적인 단위로 행 집합을 지정
RANGE : 논리적인 주소에 의해 행 집합을 지정
UNBOUNDED PRECEDING : 윈도우의 시작 위치가 첫번째 ROW
UNBOUNDED FOLLOWING : 윈도우의 마지막 위치가 마지막 ROW
CURRENT ROW : 윈도우의 시작 위치가 현재 ROW
예 > SELECT JOB, SAL
,SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) SAL1
,SAL
,SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) SAL2
,SAL
,SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) SAL3
FROM EMP
WHERE JOB = 'MANAGER'
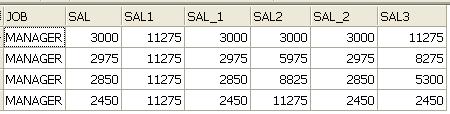
SAL1 : 첫째ROW부터 마지막ROW까지 윈도우로 설정되었으므로 전체합계
SAL2 : 첫째ROW부터 현재ROW까지 윈도우로 설정되었으므로 누적합계
SAL3 : 현재ROW부터 마지막ROW까지 설정되었으으로 누적합계의 반대개념
SELECT JOB, SAL
,SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) SAL1
,SAL
,SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) SAL2
,SAL
,SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO
ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) SAL3
FROM EMP
WHERE JOB = 'MANAGER'
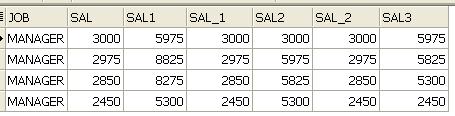
SAL1 : 현재ROW중심으로 이전과 다음ROW의 합계
SAL2 : 이전ROW와 현재ROW의 합계
SAL3 : 현재ROW와 다음ROW의 합계
 Oracle 10g SQL MODEL Clase.pdf
Oracle 10g SQL MODEL Clase.pdf
참고 : http://radiocom.kunsan.ac.kr/lecture/oracle/statement_select/model.html
http://www.oracleclub.com/article/26172
다음과 같은 seq, amt 자료가 있을때 result를 구하는 쿼리를 작성하세요.
순차적으로 amt값을 누적합산하되 그 값이 음수일경우엔 0이 되어야 합니다.
WITH t AS
(
SELECT 1 seq, -2000 amt FROM dual
UNION ALL SELECT 2, 4000 FROM dual
UNION ALL SELECT 3, -5000 FROM dual
UNION ALL SELECT 4, -2000 FROM dual
UNION ALL SELECT 5, 3000 FROM dual
UNION ALL SELECT 6, 1500 FROM dual
UNION ALL SELECT 7, -250 FROM dual
UNION ALL SELECT 8, 320 FROM dual
UNION ALL SELECT 9, -4000 FROM dual
UNION ALL SELECT 10, 10000 FROM dual
UNION ALL SELECT 11, -20000 FROM dual
)
SELECT * FROM t
|
SEQ |
AMT |
RESULT |
계산 방법 참고 |
|
1 |
-2000 | 0 | -2000 이 음수이므로 0 |
|
2 |
4000 | 4000 | 0 + 4000 = 4000 |
|
3 |
-5000 | 0 | 4000 - 5000 = -1000 = 0 |
|
4 |
-2000 | 0 | 0 - 2000 = -2000 = 0 |
|
5 |
3000 | 3000 | 0 + 3000 = 3000 |
|
6 |
1500 | 4500 | 3000 + 1500 = 4500 |
|
7 |
-250 | 4250 | 4500 - 250 = 4250 |
|
8 |
320 | 4570 | 4250 + 320 = 4570 |
|
9 |
-4000 | 570 | 4570 - 4000 = 570 |
|
10 |
10000 | 10570 | 570 + 10000 = 10570 |
|
11 |
-20000 | 0 | 10570 - 20000 = -9430 = 0 |
WITH T AS
(
SELECT 1 seq, -2000 amt FROM dual
UNION ALL SELECT 2, 4000 FROM dual
UNION ALL SELECT 3, -5000 FROM dual
UNION ALL SELECT 4, -2000 FROM dual
UNION ALL SELECT 5, 3000 FROM dual
UNION ALL SELECT 6, 1500 FROM dual
UNION ALL SELECT 8, 320 FROM dual
UNION ALL SELECT 7, -250 FROM dual
UNION ALL SELECT 9, -4000 FROM dual
UNION ALL SELECT 10, 10000 FROM dual
UNION ALL SELECT 11, -20000 FROM dual
)
SELECT SEQ, AMT, RESULT FROM T
MODEL
DIMENSION BY (SEQ)
MEASURES (AMT, 0 RESULT)
IGNORE NAV
RULES
AUTOMATIC ORDER
(
RESULT[SEQ] = GREATEST(0, RESULT[CV(SEQ) - 1] + AMT[CV(SEQ)])
)
ORDER BY SEQ
================================================================================================================
================================================================================================================
참고로 누적 구하는 쿼리
|
WITH TEST AS |
출처 : http://blog.naver.com/rainbow8830?Redirect=Log&logNo=70119741931
1. EXTRACT
- date type 의 값에서 지정한 field(년, 월, 일) 항목을 추출
+ 사용법
- SELECT EXTRACT(YEAR FROM SYSDATE) FROM DUAL : 현재 날짜에서 년도만 추출
- SELECT EXTRACT(MONTH FROM SYSDATE) FROM DUAL : 현재 날짜에서 월만 추출
- SELECT EXTRACT(DAY FROM SYSDATE) FROM DUAL : 현재 날짜에서 일 수만 추출
2. NUMTOYMINTERVAL(NUMBER, TYPE_OF_INTERVAL)
- 년, 월에 대한 시간 간격을 구함
+ 사용법
- SELECT SYSDATE - NUMTOYMINTERVAL (1, 'YEAR') FROM DUAL : 현재 날짜에서 1년을 뺌
- SELECT SYSDATE - NUMTOYMINTERVAL (1, 'MONTH') FROM DUAL : 현재 날짜에서 1달을 뺌
3. NUMTODSINTERVAL(NUMBER, TYPE_OF_INTERVAL)
- 날짜, 시, 분, 초에 대한 시간 간격을 구함
+ 사용법
- SELECT SYSDATE - NUMTODSINTERVAL (1, 'DAY') FROM DUAL : 현재 날짜에서 1일을 뺌
- SELECT SYSDATE - NUMTODSINTERVAL (1, 'HOUR') FROM DUAL : 현재 날짜에서 1시간을 뺌
- SELECT SYSDATE - NUMTODSINTERVAL (1, 'MINUTE') FROM DUAL : 현재 날짜에서 10분을 뺌
- SELECT SYSDATE - NUMTODSINTERVAL (1, 'SECOND') FROM DUAL : 현재 날짜에서 100초를 뺌
|
WITH TBL AS ( |
|
WITH TB AS ( |
출처 : http://raltigue.tistory.com/m/11
LISTAGG 함수가 도입되기 전에 동일 기능을 구현하기 위해 다양한 기법들이 사용되었다. 정리해보자.
아래와 같이 데이터를 생성하자.
CREATE TABLE t1 (c1 NUMBER(1), c2 VARCHAR2(2)); INSERT INTO t1 VALUES (1, '01'); INSERT INTO t1 VALUES (2, '02'); INSERT INTO t1 VALUES (2, '03'); INSERT INTO t1 VALUES (3, '04'); INSERT INTO t1 VALUES (3, '04'); INSERT INTO t1 VALUES (3, '05'); INSERT INTO t1 VALUES (3, '06');
① 11g를 사용한다면 LISTAGG 함수를 사용하면 된다. 집계함수(1번)와 분석함수(2번) 형태로 사용이 가능하다.
-- 1
SELECT a.c1,
LISTAGG (a.c2, ',') WITHIN GROUP (ORDER BY a.c2) AS c2
FROM t1 a
GROUP BY a.c1;
C1 C2
--- ------------
1 01
2 02,03
3 04,04,05,06
3 rows selected.
-- 2
SELECT a.c1,
LISTAGG (a.c2, ',') WITHIN GROUP (ORDER BY a.c2) OVER (PARTITION BY A.c1) AS c2
FROM t1 a;
C1 C2
--- ------------
1 01
2 02,03
2 02,03
3 04,04,05,06
3 04,04,05,06
3 04,04,05,06
3 04,04,05,06
7 rows selected.
② WM_CONCAT 함수는 WMSYS 유저가 내부적으로 사용한다. (SQL Reference에 없다...--;) LISTAGG보다 성능은 떨어지지만 추가 기능(DISTINCT 구문, 분석함수 누적, KEEP 절)을 지원한다. 4번 방식을 이용하면 정렬도 가능하다.
-- 1
SELECT a.c1,
wmsys.wm_concat (a.c2) AS c2
FROM t1 a
GROUP BY a.c1;
C1 C2
--- ------------
1 01
2 02,03
3 04,06,05,04
3 rows selected.
-- 2
SELECT a.c1,
wmsys.wm_concat (DISTINCT a.c2) AS c2
FROM t1 a
GROUP BY a.c1;
C1 C2
--- ------------
1 01
2 02,03
3 04,05,06
3 rows selected.
-- 3
SELECT a.c1,
wmsys.wm_concat (a.c2) OVER (ORDER BY a.c2) AS c2
FROM t1 a;
C1 C2
--- ----------------------
1 01
2 01,02
2 01,02,03
3 01,02,03,04,04
3 01,02,03,04,04
3 01,02,03,04,04,05
3 01,02,03,04,04,05,06
7 rows selected.
-- 4
SELECT a.c1,
MAX (CAST (a.c2 AS VARCHAR2 (4000))) as c2
FROM (SELECT a.c1,
wmsys.wm_concat (a.c2) OVER (PARTITION BY a.c1 ORDER BY a.c2) AS c2
FROM t1 a) a
GROUP BY a.c1;
C1 C2
--- ------------
1 01
2 02,03
3 04,04,05,06
3 rows selected.
-- 5
SELECT a.c1,
wmsys.wm_concat (a.c2) KEEP (DENSE_RANK FIRST ORDER BY a.c2) AS c2
FROM t1 a
GROUP BY a.c1;
C1 C2
--- ------------
1 01
2 02
3 04,04
3 rows selected.
③ 10g에서는 XMLAGG 함수를 사용해도 된다.
SELECT a.c1,
SUBSTR (XMLAGG (XMLELEMENT (a, ',', a.c2) ORDER BY a.c2).EXTRACT ('//text()'), 2) AS c2
FROM t1 a
GROUP BY a.c1;
C1 C2
--- ------------
1 01
2 02,03
3 04,04,05,06
3 rows selected.
④ 후임자를 괴롭히고 싶다면 MODEL 절을 사용해도 된다...--;
SELECT a.c1,
RTRIM (a.c2, ',') as c2
FROM (SELECT c1,
c2,
rn
FROM t1 a
MODEL PARTITION BY (a.c1)
DIMENSION BY (ROW_NUMBER() OVER (PARTITION BY a.c1 ORDER BY a.c2) AS rn)
MEASURES (CAST (a.c2 AS VARCHAR2(4000)) AS c2)
RULES (c2[ANY] ORDER BY rn DESC = c2[CV()] || ',' || c2[CV()+1])) a
WHERE a.rn = 1
ORDER BY a.c1;
C1 C2
--- ------------
1 01
2 02,03
3 04,04,05,06
3 rows selected.
⑤ 9i에서는 전통적 방식인 ROW_NUMBER와 SYS_CONNECT_BY_PATH 조합을 사용하면 된다.
SELECT a.c1,
SUBSTR (MAX (SYS_CONNECT_BY_PATH (a.c2, ',')), 2) AS c2
FROM (SELECT a.c1,
a.c2,
ROW_NUMBER () OVER (PARTITION BY a.c1 ORDER BY a.c2) AS rn
FROM t1 a) a
START WITH a.rn = 1
CONNECT BY a.c1 = PRIOR a.c1
AND a.rn - 1 = PRIOR a.rn
GROUP BY a.c1
ORDER BY a.c1;
C1 C2
--- ------------
1 01
2 02,03
3 04,04,05,06
3 rows selected.
